

So, you run your app, and you get an exception. Something with EF, or your SQL statements, but mostly, you can see something is wrong with the database (again). You shout across the room: "Did anybody touch the database?" and you hear the dreaded answer: "Yeah, I did. Am just about to check-in some changes, can you wait?". Sounds familiar?
For us "regular" software developers, the database is a thing somewhere on a distant server, that holds our data hostage. It's run by ye-old Database Admin, and it's hard to get anything across to him. We do everything we can, to abstract it away, deep into some lowest level of our architecture. However, the unfortunate part is, we need that database server, because it's still one of the best ways to store the data. Sure, there are fancy buzzwords floating around, like NoSQL and schema-less databases, but, all in all, most apps need a place to store the data.
Centralized Changes = Conflicting Changes
So, now we have an application - let's say it's a bit more complex, and it's N-tier. We have a team of developers working on it, ideally using an Agile approach, like Scrum methodology. In an agile approach, each developer will generally contribute a (value-add) feature from top to bottom. That's why you want a well rounded, full stack team. But that also means that someone might start to work on a user story that modifies the data scheme. Not a problem, right? Unless you are still using that one centralized development server.
If you have a centralized server and all your machines are connected to that server, you get the benefit of having a lot of test data (some of it, by the way, invalid, etc.), but everytime someone touches the schema, if they didn't check-in the code change, it brings down your build. So that is generally considered a bad thing.
Local Database to the rescue
So, since the beginning of time, developers installed SQL server to our own machines. And it was good. We had complete control, we made our mistakes, but we survived. We did the changes, and then we wrote the code, and hopefully synced the changes to the development server. This process was then repeated for the Dev <-> Staging, and Staging <-> Production pairs. And it sort of worked. Sometimes people forgot to sync the changes, but someone was bound to catch that problem and track down the person responsible.
Until continuous deployment & integration started getting widespread adoption. Now, all of a sudden, there were tests being run on each check-in, and code being deployed to the servers. So if someone forgets to check-in code, what happens? A failed build/deploy. In my current team, that means 1 € to the piggy. Trust me, that can get pretty expensive, if you are careless, or if you have a "bad" developer on your team (on a side note, I wrote a post on Medium about dealing with bad developers).
Change Scripts
So, here is one approach on how you can solve this. Change Scripts. Basically, you require everyone to always write a change script. Anything you need done on the database, needs to be expressed using a change script. You start with something like 1001 - Setup initial structure.sql and you work your way from there. The 1 prefix, btw, is because sorting is still impossible, if you do 0001, ... :-) Ah, Windows.
Then, you have a tool, or a library, you can run, that runs each script (that has not yet been run), and with that, upgrades the database.
Our initialization script also contains the following:
CREATE TABLE [settings].SchemaUpdates(
[IdSchemaUpdate] [bigint] IDENTITY(1,1) NOT NULL,
[ScriptFileName] [nvarchar](max) NOT NULL,
[ExecutedAtUtc] DATETIME NOT NULL CONSTRAINT DV_SchemaUpdates_ExecutedAtUtc DEFAULT GETUTCDATE(),
CONSTRAINT [PK_SchemaUpdates] PRIMARY KEY CLUSTERED
(
[IdSchemaUpdate] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
The script that we use (which is a batch script that I've been carrying around on various projects forever) takes a look at this table, reads the latest script that executed and executes all newer scripts. It's rudimentary, but it gets the job done. I also have some OWIN Middleware written (in our infrastructure projects), that is able to print out which scripts have been installed.
We execute this script locally, by hand, and automatically on each build for the dev server. The problem with this is, it doesn't really comply with the "single-step" build process. But it works, and it's a tradeoff I am willing to make. All the files are included into a Class Library Project called "Database" that has no output and is set to not build. But it is a part of the solution, and it helps me create the artifacts inside Visual Studio Online Build.
So, the artifacts look a little something like this:
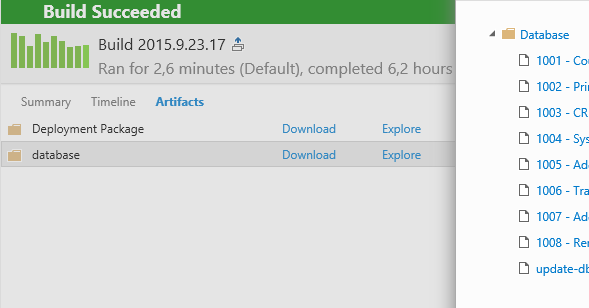
The first artifact is our "Deployment Package" which contains zip files for all the different web applications in our solution. If you want to see how I did it, I write about it in this blog post. The next one is the "Database" and this contains the upgrades to the schema (1001 - 1008 in the screenshot above), and the update-db.bat file, which performs the migration.
DbUp
While the above solution works, sometimes soon, though, I plan on migrating to DbUp. DbUp is an open-source tool that does exactly that. But the nice part is, it's code. That means you can either build your own console app (erm, much better than that batch file I talked about above), or use PowerShell for it.
You still have that project, e.g. a Class Library, and the files are included - only this time, you want to embedd them as a resource. Inside the Main class, though, you can simply have:
var upgrader =
DeployChanges.To
.SqlDatabase(connectionString)
.WithScriptsEmbeddedInAssembly(Assembly.GetExecutingAssembly())
.LogToConsole()
.Build();
Now that is exciting. You can still run this application as part of your deployment process (return -1 or 0 to tell the build server something is wrong), or, what I think is an even better alternative, you can implement a maintanence mode for your application, that enables the app to basically self-upgrade. And DbUp also allows you to provide custom "code scripts", which means you can start introducing much more custom migration logic.